import pandas as pd
import matplotlib.pyplot as plt
import numpy as npf = "../data/tbd_9horas.parquet"
tdb = pd.read_parquet(f)
tdb.info()<class 'pandas.DataFrame'>
DatetimeIndex: 44983 entries, 2023-06-01 09:00:00 to 2025-06-19 09:59:00
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 tdb 44983 non-null float64
dtypes: float64(1)
memory usage: 702.9 KBfig, ax = plt.subplots( figsize=(12, 4))
mu = tdb.tdb.mean()
sigma = tdb.tdb.std()
x = np.linspace(tdb.min(), tdb.max(), 200)
pdf = (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
ax.hist(tdb, bins=40, density=True, alpha=0.6)
ax.plot(x, pdf, 'r-', lw=2, label=f'μ={mu:.2f}, σ={sigma:.2f}')
ax.legend(fontsize=8)
plt.tight_layout()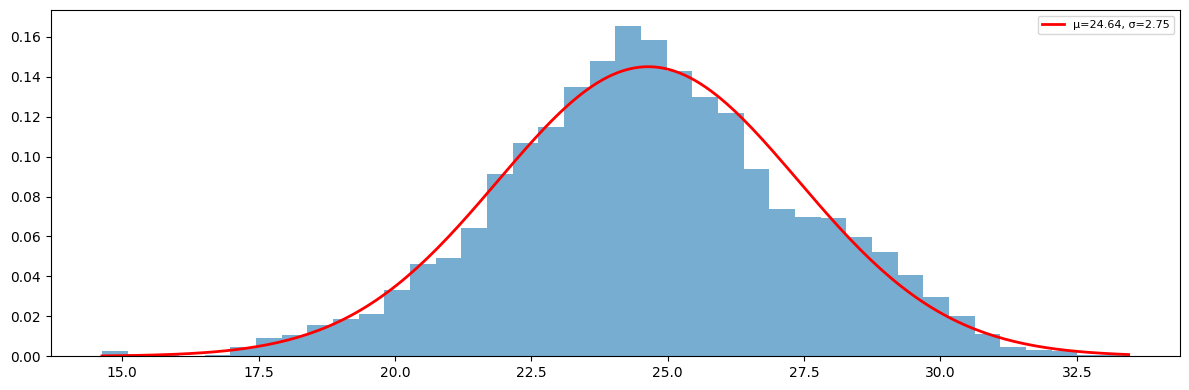
N = 5
muestra = tdb.tdb.sample(n=N, random_state=42)
fig, ax = plt.subplots()
x = np.linspace(tdb.min(), tdb.max(), 200)
pdf = (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
ax.hist(muestra,bins=40,density=True)
ax.plot(x,pdf)
plt.show()
print(muestra.mean(),muestra.std())
print(mu,sigma)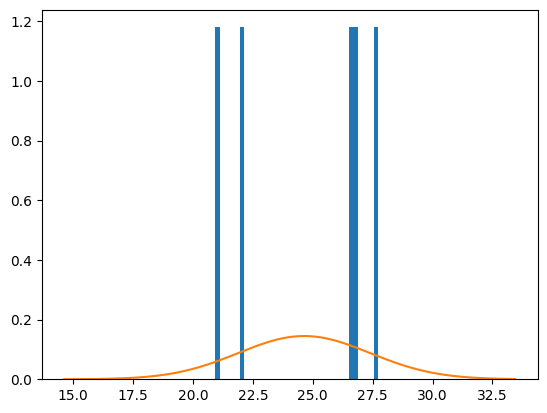
24.823999999999998 3.080946283205859
24.64268657048218 2.7513050667323573